Agent Skills 是什么?和 Prompt、MCP 到底差在哪?
团队里有套完整的代码审查规范,想让 Claude 按这个来 review。最直接的做法是每次粘到 Prompt 里——它倒是照做了,但下次换个会话,换个同事,又得粘一遍。
后来有人说放进 AGENTS.md,情况好一些,但又不知道该放多少合适:规范太长了模型会不会忽略中间那几段?哪些约定是全局的,哪些只在某类任务里才有用?
这类问题,Agent Skills 正好能接住。
本文接近 9000 字,建议收藏,通过本文你将搞懂:
- Skill 到底是什么,以及它和 Prompt、Function Calling、MCP 在实际链路里怎么配合
- SKILL.md 怎么写——元数据、正文结构、自由度怎么把控
- 延迟加载、工作流设计、路由策略的实操思路,以及写 Skill 最容易踩的 8 个坑
Agent Skills 是什么?
简单说,Skill 是一份可被 Agent 发现、按需加载的任务说明。
它会把某类任务的经验、约束和执行顺序沉淀下来,让 Agent 在需要时再读。接口返回格式怎么统一,日志字段怎么打,慢 SQL 怎么查,Review 时先看架构还是先看异常处理——以前这些东西要么散在文档里,要么靠人反复提醒,Skills 给了它们一个固定落脚点。
所以,不要把 Skill 想成一个神秘的新能力。它更像是把“老员工脑子里的规矩”写进 SKILL.md,再交给 Agent 在合适的任务里调用。
Skill 和 Prompt、MCP、Function Calling 有什么联系?
先说结论:Skill 不是 Prompt、MCP、Function Calling 的替代品,它们也不是同一层的四个竞品。放到一条 Agent 执行链路里看,关系会清楚很多。
用户说一句“帮我分析这份报表”,这是 Prompt。模型判断需要调用 read_file,并生成结构化参数,这是 Function Calling。read_file 这个能力如果来自 MCP Server,那 MCP 负责的是连接和协议。至于“分析报表时先看字段含义,再看异常值,最后给业务结论,不要直接堆统计指标”,这才是 Skill 适合放的东西。
放在一个真实链路里,大概是这样:
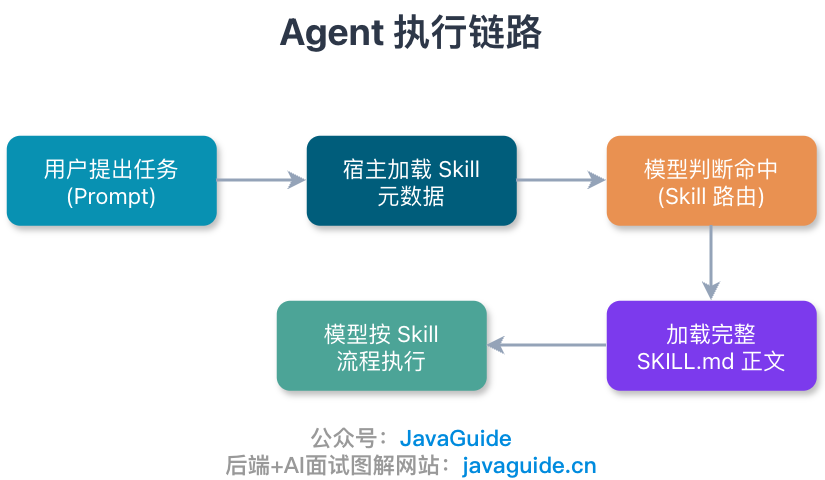
- 用户提出任务(Prompt)
- 宿主把可用 Skills 的简短描述放进上下文(Skill 元数据)
- 模型判断当前任务命中了某个 Skill(Skill 路由)
- 宿主再把完整
SKILL.md加载进来(延迟加载) - 模型按照 Skill 里的流程去调工具、读资料、写结果(执行)
注意重点:Skill 把复杂任务的做法提前写下来,至于执行时调不调工具看具体场景。有的 Skill 全程不需要外部工具,比如 sanyuan-skills 里的 Code Review Expert,它只是告诉模型从 SOLID、安全、性能等维度依次审查;有的 Skill 会一路调 MCP、跑脚本、读参考文件,比如 Superpowers 里的 TDD 技能,它会让 Agent 执行测试命令、分析输出、再决定下一步。
所以不建议把 Skill 说成“基于 Function Calling 的封装”,这个说法容易把人带偏。Function Calling 是执行动作时可能用到的底层能力,Skill 本身更像上下文注入机制:Agent 读一份文档,然后把里面的规则纳入后续推理。
load_skill() 也要这样理解:它不是所有工具里都存在的统一 API 名字,更像一个概念,表示宿主在合适的时候读取并激活 SKILL.md。Claude Code、Cursor、Codex、Copilot 这些工具的触发细节会有差异,别把它当成跨平台标准函数。
⭐️SKILL.md 到底怎么写?
基本结构
最小可用的 Skill 其实很简单,就是一个目录加一个 Markdown 文件 SKILL.md。
scripts/、references/、assets/ 这些都不是必需项,但复杂点的 Skill 经常会用到这些文件夹,例如 scripts/ 中放一些 Skill 需要用到的脚本。
skill-name/
├── SKILL.md # 主文件,触发时加载
├── scripts/ # 实用脚本(执行,不需要加载到上下文)
├── references/ # 参考资料(按需加载)
└── assets/ # 模板和静态文件(按需加载)简单来说,SKILL.md 分两部分:
- 前面是 YAML 前置元数据,告诉宿主“我是谁、什么时候该用我”;
- 后面是正文,写具体流程、约束、示例和失败处理。
想要学 Skill 怎么写,我们直接看最顶级的开源 Skill 就好了。
这里我们以 Superpowers 的 TDD 技能为例,
它的元数据只有两行:
---
name: test-driven-development
description: Use when implementing any feature or bugfix, before writing implementation code
---TDD 会涉及到 Red-Green-Refactor 循环,但这个 TDD Skill 的 description 压根没提到,就一句话说清楚什么时候该用。正文才展开讲具体怎么做,简化版如下:
# TDD
## Rule
Write a failing test before production code.
If you did not watch the test fail, the test is not trusted.
## Flow
1. **RED**: Write one small failing test.
2. **VERIFY RED**: Run it. Confirm it fails for the expected reason.
3. **GREEN**: Write the smallest code to pass.
4. **REFACTOR**: Clean up without changing behavior.
## Use For
- Features
- Bug fixes
- Refactoring
- Behavior changes
## Ask Before Skipping
- Throwaway prototypes
- Generated code
## Done Checklist
- [ ] Test written first
- [ ] Failure observed
- [ ] Minimal code added
- [ ] Tests pass先看官方的 skill-creator
Anthropic 官方 Skills 仓库里有一个很适合参考的 Skill,叫 skill-creator。
它本身就是一个“用来创建 Skill 的 Skill”,可以用来创建新 Skill、修改已有 Skill、测试效果,还能帮你优化 description 的触发准确性。
它会先引导 Agent 把问题想清楚:这个 Skill 到底解决什么任务?什么时候该触发?边界在哪里?哪些内容放进 SKILL.md,哪些内容应该拆到 scripts/ 或 references/?
这个例子值得看,主要有两点。
第一,它很重视 description。description 不是随便写一句“帮助处理某某任务”就行,它会直接影响 Skill 能不能在正确场景下被触发。
第二,它不会只盯着 SKILL.md。复杂一点的 Skill,通常不应该把所有东西都塞进主文件。能用脚本稳定执行的,就放到 scripts/;比较长的说明、检查清单、参考资料,可以拆到 references/。
Claude 官方帮助文档也提到,如果单个 Skill.md 信息太多,可以把只在特定场景需要的内容拆成额外文件,再从 Skill.md 里引用,让 Claude 按需访问。
不过,也没必要把 skill-creator 当成唯一标准答案。它更适合当学习入口。真正写自己的 Skill 时,还是那句话:主文件只放 Agent 当前任务必须读的内容,细节能拆就拆。
元数据(Frontmatter)
元数据决定 Skill 能不能被正确发现和触发。一般来说,至少要写清楚两个字段:name 和 description。
name 就是 Skill 的标识,主要给系统和人定位用;description 则更像路由说明,告诉 Agent 什么时候该把这个 Skill 加载进来,也就是什么时候用。
先看 name。它有几个硬性要求:
- 最多 64 个字符
- 只能包含小写字母、数字和连字符
- 不能包含 XML 标签
- 不能包含保留字,比如
anthropic、claude
命名时可以优先用动名词形式,也就是“动词 + -ing”。这样一眼就能看出这个 Skill 提供的是什么能力。
| 好的命名 | 不好的命名 |
|---|---|
processing-pdfs | helper、utils,太模糊 |
reviewing-code | documents,太通用 |
test-driven-development | tools,啥也没说 |
analyzing-spreadsheets | anthropic-helper,包含保留字 |
description 更关键。如果description 写的不好,那这个Skill 就没办法在该调用的时候被调用。毕竟 Agent 不会先把每个 Skill 的 SKILL.md 都读一遍,而是先看描述来判断该不该加载。
description的描述不能太简洁,也不要太多。一个好用的 description,建议说清楚两件事就足够了:
- 这个 Skill 做什么
- 在什么场景下需要用它
我们前面列举的 Superpowers 的 TDD 技能就是满足这个要求的。
最好再带上一些用户可能会说出来的词。比如 PDF、表单、提取、提交消息、git diff 这类词。这样不管是规则匹配还是语义匹配,都更容易抓到。
# ✓ 好的:有能力、有场景、有触发词
description: 从 PDF 文件中提取文本和表格、填充表单、合并文档。在处理 PDF 文件或用户提及 PDF、表单、文档提取时使用。
# ✗ 避免:第一人称 + 触发条件不清楚
description: 我可以帮助您处理 PDF 文件
# ✗ 避免:只写能力,不写什么时候用
description: 处理 Excel 文件看几个实际例子:
# Superpowers 的 TDD
name: test-driven-development
description: Use when implementing any feature or bugfix, before writing implementation code
# sanyuan-skills 的 Code Review Expert
name: code-review-expert
description: Expert code review of current git changes with a senior engineer lens. Detects SOLID violations, security risks, and proposes actionable improvements.
# Git 提交助手
description: 通过分析 git diff 生成描述性提交消息。当用户要求帮助编写提交消息或审查暂存更改时使用。反过来,下面这些写法就不太合适了:
# Superpowers 的 TDD 反例,只写概念,不写触发时机
name: test-driven-development
description: Helps with test-driven development and writing better tests.
# Code Review Expert 反例,太泛
name: code-review-expert
description: Helps review code and improve quality.
# Git 提交助手反例,只写功能名
description: 生成提交消息。正文
正文是 Agent 真正要读的“操作手册”。
这里有个容易被忽略的点:Skill 不是一上来就把全部内容塞进上下文。通常启动时先加载的是元数据,也就是 name 和 description;只有模型判断这个 Skill 和当前任务相关时,才会继续读取 SKILL.md 正文。这个设计本身就是为了省上下文。
但这不代表正文可以随便写。一旦 SKILL.md 被加载进来,里面的每一个 token 都会和系统提示、对话历史、用户请求、其他上下文一起竞争注意力。
所以写正文之前,先想清楚一件事:
上下文窗口是公共资源。不是塞得越多,Agent 表现就越好。上下文越长,模型需要在更多信息里找关键线索,真正重要的规则反而可能被冲淡。
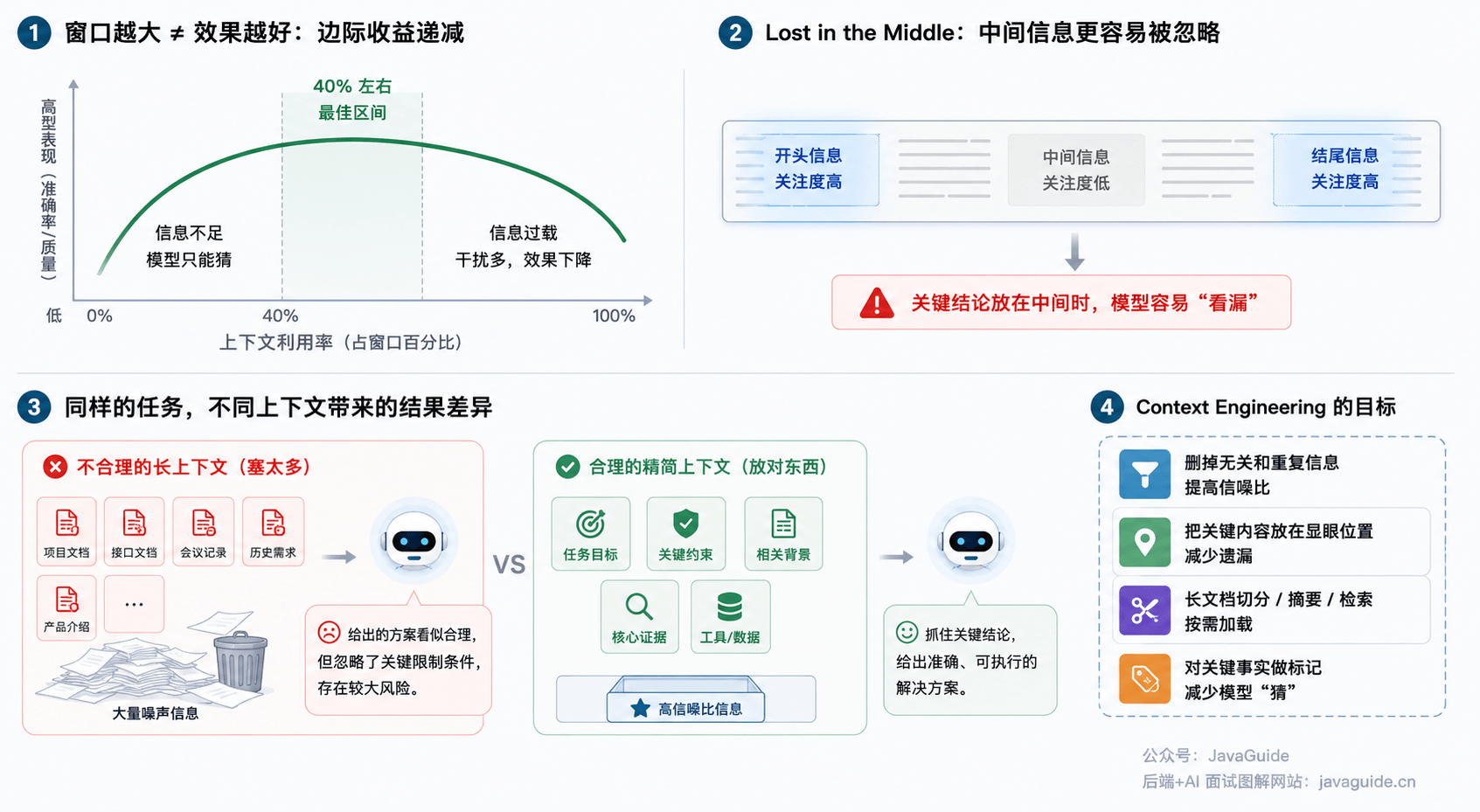
不要把 Skill 写成科普文,也不要把它写成 README。正文只放 Agent 执行任务时真正需要的信息。
每写一段,都可以问自己三个问题:
- Agent 真的需要这段解释吗?
- 这是项目里的私有知识,还是通用常识?
- 这段话值不值得占用上下文?
举个例子。
好的写法:
## 提取 PDF 文本
使用 pdfplumber 进行文本提取:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```不太好的写法:
## 提取 PDF 文本
PDF(便携式文档格式)是一种常见文件格式,通常包含文本、图片和其他内容。
如果要从 PDF 中提取文本,需要使用专门的 PDF 处理库。
目前有很多库可以完成这类工作,例如 pypdf、pdfplumber、PyMuPDF 等。
这里建议使用 pdfplumber,因为它比较容易上手,也能覆盖大多数普通 PDF 文本提取场景。
首先,你需要使用 pip 安装它,然后再编写下面的代码……第二种写法看着更完整,但其实都是废话和误导信息,对 Agent 来说没什么价值。Agent 压根不需要你解释 PDF 是什么,也不需要你介绍一圈常见库。它真正需要的是:默认用什么、怎么调用、输出怎么处理、遇到特殊情况怎么办。
Skill 正文里最值钱的内容,往往不是概念解释,而是踩坑清单。
比如:
users 表使用软删除。所有正式查询都必须加 `WHERE deleted_at IS NULL`。这种信息 Agent 猜不到,必须写。
但下面这种就没必要:
软删除是一种常见的数据删除方式,通常不会真正删除数据库记录,而是通过字段标记记录状态。这就是通用常识,放进正文里只会占上下文。
正文还有一个很实用的原则:主文件别太长。
Anthropic 的建议是,SKILL.md 正文最好控制在 500 行以内;如果超过这个长度,就把细节拆到单独文件里,通过渐进式披露的方式让 Agent 按需读取。
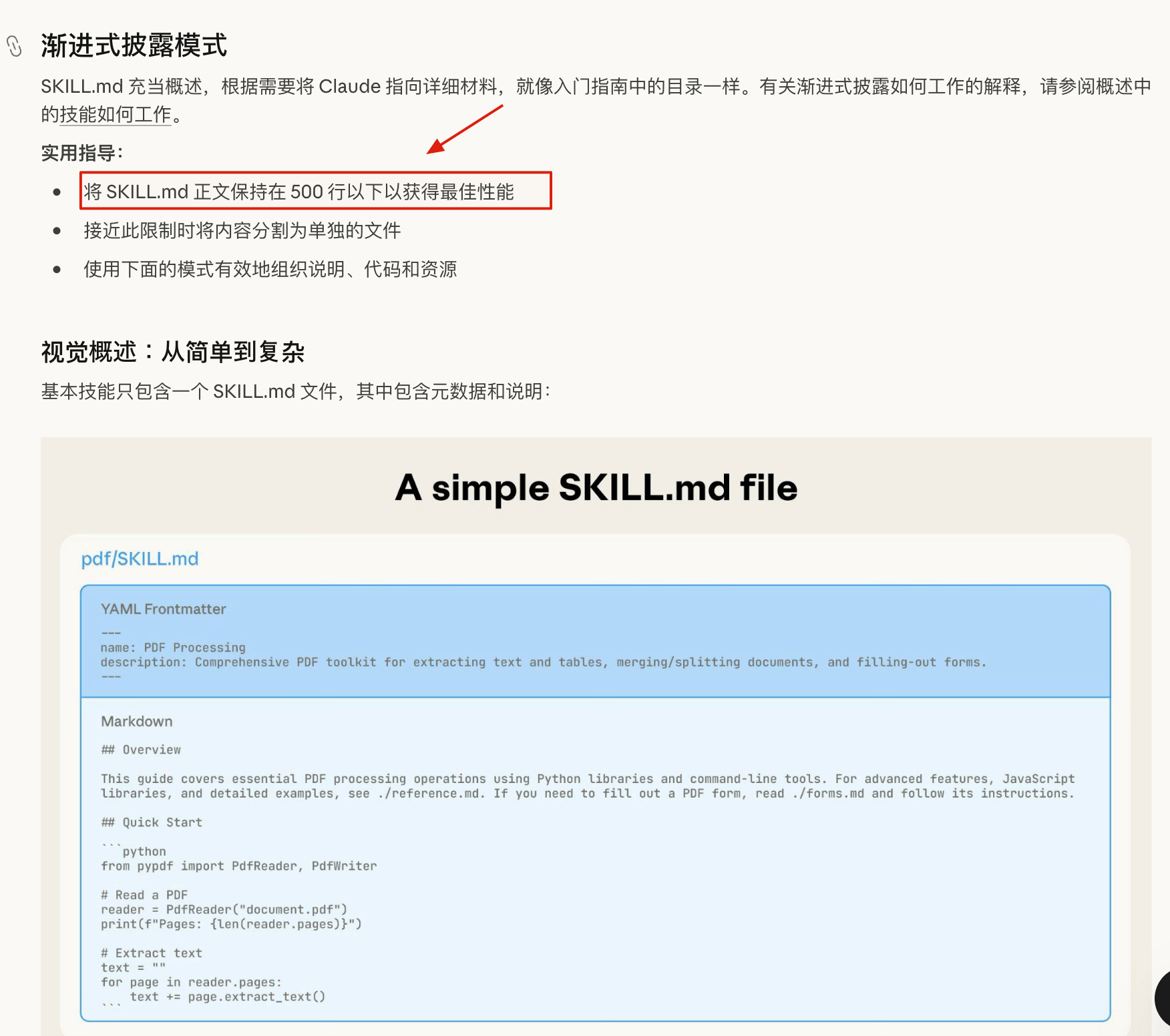
比如 Code Review Skill 不一定要把所有 SOLID 检查项都塞进主文件。主文件只需要写:
需要做 SOLID 设计检查时,读取 `references/solid-checklist.md`。具体 checklist 放到 references/solid-checklist.md 里。这样 Agent 只有在真的需要做设计检查时,才会把这部分内容读进来。
可以参考几个开源 Skill 集合:
- Superpowers:包含 TDD、brainstorming、代码审查等 Skill,TDD 那个结构很清楚,适合看正文怎么组织。
- sanyuan-skills:Code Review Expert 把更细的检查项拆进
references/,主文件只保留触发和加载说明,适合作为渐进式披露的例子。 - Anthropic 官方 Skills 仓库:目录结构和写法可以作为基准参考。
在 Claude Code 这类工具里,Skill 不一定非要你手动点。你可以用 /skill-name 主动调用,也可以让 Claude 根据当前任务自己判断要不要用。
传统插件更像“我点一下,你执行一下”;Skills 更像一包提前整理好的经验。模型先看描述,觉得当前任务对得上,再去读里面的流程、约束、脚本和参考文件。
自由度怎么把控?
写 Skill 时还有个问题很容易被忽略:你到底要让 Agent 自己发挥到什么程度?
这个没有固定答案,得看任务风险。
可以简单这么理解:如果任务出错代价很高,就别给太多自由度;如果任务本身需要判断和取舍,就别把步骤写死。
比如数据库迁移、生产部署这类任务,就不适合让 Agent 自由发挥。你不能写一句“请根据情况迁移数据库”,然后指望它自己判断要不要备份、要不要校验、要不要回滚。这个场景就应该写清楚命令、参数、顺序,最好还要明确一句:不要改命令。
但像代码审查、技术方案评估这种任务,情况就不一样了。它本来就需要结合上下文判断,强行写死每一步,反而会让 Agent 变笨。你可以给检查维度,比如安全、性能、可维护性、项目约定,但具体看哪里、怎么判断,要留一点空间。
大概可以分成三类:
| 自由度 | 适合场景 | 写法 |
|---|---|---|
| 高 | 需要判断和取舍,答案不唯一 | 给检查方向,不写死步骤 |
| 中 | 有固定模板,但允许按场景调整 | 给模板、参数和边界 |
| 低 | 操作脆弱,出错代价高 | 给精确命令,明确不能改 |
举个例子,Superpowers 的 TDD Skill 其实就是“局部低自由度”。
它的 Iron Law 写得很硬:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST这条规则没什么商量空间。红、绿、重构的顺序也不能乱。你不能跳过失败测试直接写实现,也不能先写完代码再回来补测试。它甚至写了:
Write code before the test? Delete it. Start over.这就是低自由度:流程不能变,红线不能碰。
但它也不是所有地方都写死。具体测哪个行为、测试名怎么写、断言怎么设计,这些还是要根据当前功能判断。所以更准确地说,它是“流程低自由度,具体测试高自由度”。
再看 sanyuan-skills 的 Code Review Expert,它会给一些固定审查维度,比如 SOLID、安全风险、性能问题、可维护性。但代码审查本身很难完全模板化,因为不同项目的问题不一样。
所以它更像是:检查框架固定,具体判断留给 Agent。
低自由度的写法可以这样:
## 数据库迁移
运行下面这条命令:
```bash
python scripts/migrate.py --verify --backup
```
不要修改命令,不要添加额外参数。
如果命令失败,停止执行,并把错误输出返回给用户。这种场景里,重点是稳定,不是灵活。
高自由度的写法可以这样:
## 代码审查
重点检查:
1. 是否有明显 Bug 或边界情况遗漏
2. 是否存在安全风险
3. 是否影响性能或资源使用
4. 是否违反项目已有约定
5. 是否有更简单的实现方式
输出时优先写会影响正确性和线上稳定性的问题,不要只做格式建议。这种写法没有规定 Agent 必须按哪个文件、哪一行、哪个顺序检查,但给了它判断方向,也限制了输出重点。
我自己的建议是:凡是会改数据、发请求、部署、迁移、删除文件的任务,自由度都要收紧;凡是分析、评审、总结、生成草稿类任务,可以适当放开。
Skill 不是越详细越好,也不是越自由越好。关键是看这个任务“错一步”的代价有多高。代价高,就把路铺窄一点;代价低、判断空间大,就别把 Agent 绑得太死。
⭐️延迟加载与渐进式披露
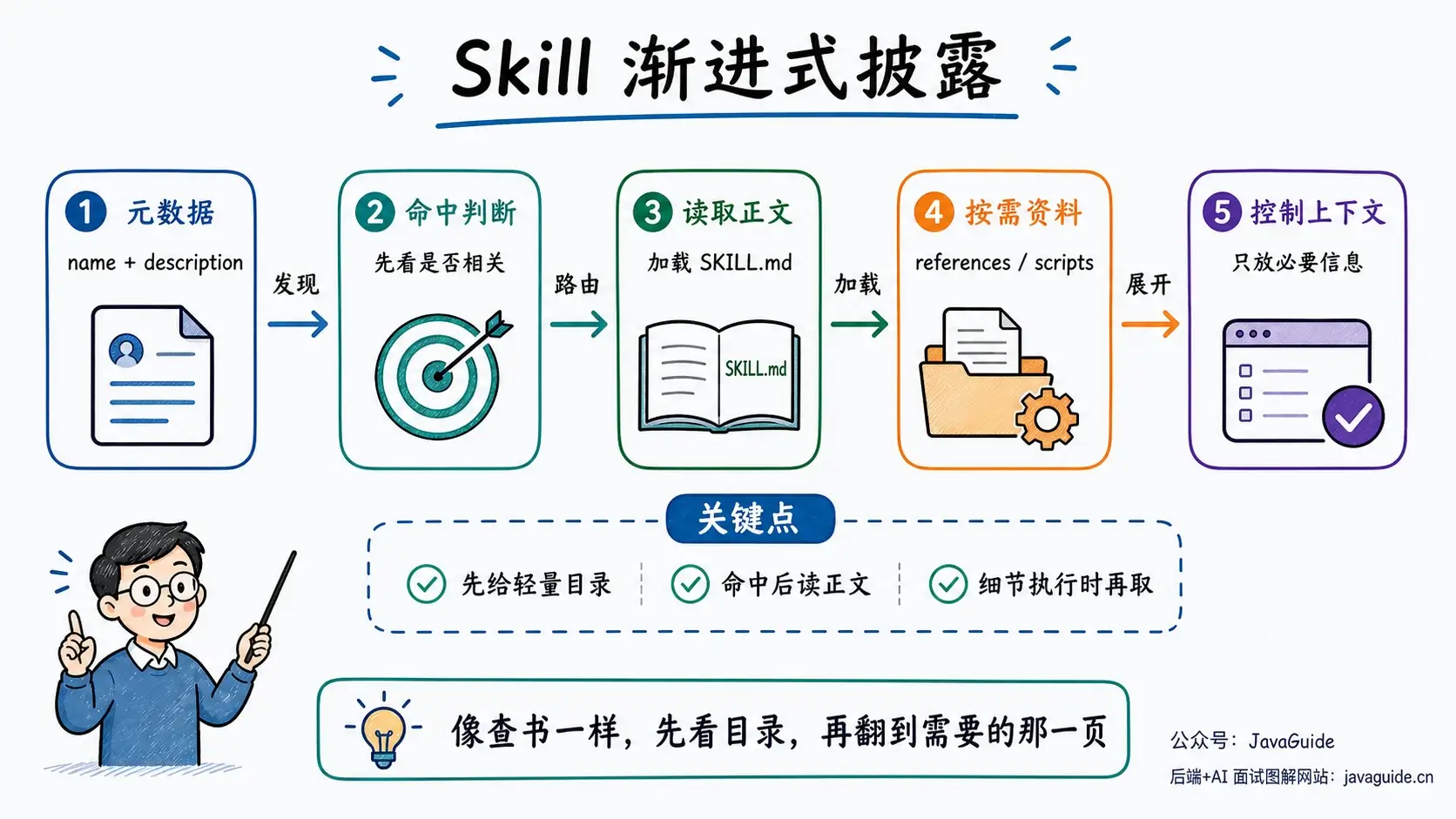
为什么不能把所有 Skill 一次性全塞进去?
Agent 的上下文窗口是有限的,至少现在还是这样。
而且,窗口大了只是能装下更多内容,不代表它能自动挑出重点。比如你给它分析一份长需求文档,真正关键的限制条件可能就三句话,但夹在各种背景和说明中,模型很容易忽略中间的那些关键句。
这就是大家常说的 Context Rot,上下文腐化。上下文越长,信息越杂,模型利用上下文的稳定性就越可能变差。
跟它相关的还有一个经典现象叫 Lost in the Middle——模型对开头和结尾的信息更敏感,对夹在中间的东西更容易“看漏”。所以有时候你明明把资料给它了,它还是答错,不一定是没读到,而是关键内容在长上下文里不够显眼。
所以,Skill 不应该写成资料库。
更好的方式是渐进式披露:先给模型一份轻量目录,真正用到哪块,再去加载哪块。

就像查书一样。你不会先把整本书背下来,而是先看目录,确定章节,再翻到具体那一页。
一般可以分成三层:

1. 广告层:先让模型知道有这个 Skill
启动时通常只加载 Skill 的元数据,比如 name 和 description。这部分很短,用来告诉模型:我是谁,我适合什么场景。
2. 指令层:命中后再读正文
当 Agent 判断当前任务确实相关时,才读取对应的 SKILL.md 正文。正文里放流程、规则、边界和关键示例。这里不要写太长,Anthropic 的建议是正文尽量控制在 500 行以内。
3. 资源层:执行时再读细节
如果正文里引用了 references/、scripts/ 这类文件,Agent 再按需读取或执行。比如只是执行脚本,通常只需要把脚本输出放进上下文;如果要阅读或修改脚本,那源码才需要进上下文。
所以你会经常看到这种写法:
## 高级功能
**表单填充**:完整指南请参阅 [FORMS.md](FORMS.md)
**API 参考**:所有方法请参阅 [REFERENCE.md](REFERENCE.md)Agent 只有在真的要处理表单时,才会去读 FORMS.md。如果当前任务只是普通文本提取,这个文件就不用进上下文。
实际项目中怎么组织文件?
以一个数据分析类 Skill 为例,可以这么拆:
bigquery-analysis/
├── SKILL.md # 概述和导航,命中时加载
└── reference/
├── finance.md # 收入、ARR、账单指标
├── sales.md # 机会、管道、账户
├── product.md # API 使用、功能采用
└── marketing.md # 活动、归因、电子邮件主文件不要把所有数据口径都写进去,只做导航:
# BigQuery 数据分析
## 可用数据集
**财务**:收入、ARR、账单 → 参阅 [reference/finance.md](reference/finance.md)
**销售**:机会、管道、账户 → 参阅 [reference/sales.md](reference/sales.md)
**产品**:API 使用、功能采用 → 参阅 [reference/product.md](reference/product.md)
**营销**:活动、归因、电子邮件 → 参阅 [reference/marketing.md](reference/marketing.md)用户问“上个季度的销售管道怎么样”,Agent 读完 SKILL.md 后,只需要打开 reference/sales.md。财务、产品、营销这几份文件不用读,也就不会占上下文。
不要写成这样:
SKILL.md → advanced.md → details.md → 最关键的规则藏在这里更稳的写法是一级引用:
SKILL.md
├── 直接包含基本用法
├── 高级功能 → advanced.md
└── API 参考 → reference.md也就是说,主文件里就把可用资料列出来,让 Agent 一步就能跳到目标文件。
如果参考文件比较长,建议在文件顶部放一个简短目录。就算 Agent 只先扫了开头,也能知道这个文件里有哪些内容。
工作流和反馈循环怎么设计?
简单点的任务,写几条规则就够用了。但遇到复杂一些的场景,这样做就不太够了。
Agent 很可能会跳过一些步骤,例如检查输出质量、跑测试代码,然后直接说它已经做完了。
为了避免这种问题,需要写清楚这两个点:
- 每一步按什么顺序走
- 哪些地方必须停下来验证
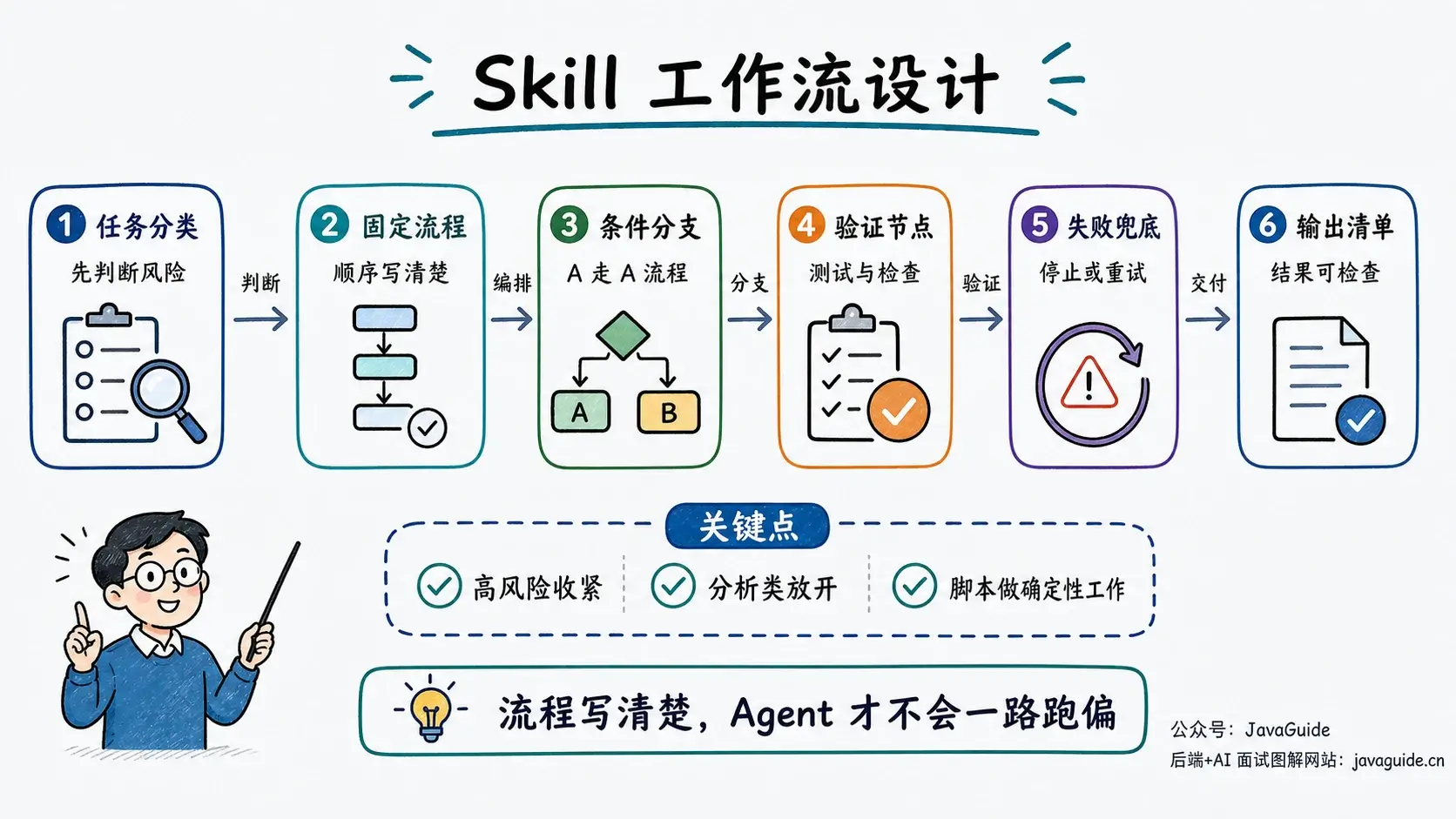
图示:复杂 Skill 要把任务分类、条件分支、验证节点和失败兜底写进流程里。
用清单把步骤串起来
Superpowers 的 TDD Skill 就是一个很好的例子。
它没有只写一句“先写测试,再写代码”。这种话太粗了,Agent 真执行时还是容易糊弄过去。
它是直接把流程拆成了几个明确阶段,简化版本如下:
### RED - Write Failing Test
Write one minimal test showing what should happen.
### Verify RED - Watch It Fail
**MANDATORY. Never skip.**
Confirm:
- Test fails, not errors
- Failure message is expected
- Fails because feature missing, not typos
### GREEN - Minimal Code
Write simplest code to pass the test.
Don't add features.
### REFACTOR - Clean Up
After green only:
- Remove duplication
- Improve names
- Extract helpers
Keep tests green. Don't add behavior.这里最关键的,其实不是 RED、GREEN、REFACTOR 这几个名字,而是中间的 Verify RED。
它要求 Agent 必须先看到测试失败,而且失败原因要对。不是路径错了,不是语法错了,也不是测试本身写崩了,而是因为功能还没实现,所以失败。
这一步如果不写清楚,Agent 很容易直接写实现,然后补一个“看起来能过”的测试。这就不是 TDD 了。
它最后还放了一份验证清单:
## Verification Checklist
Before marking work complete:
- [ ] Every new function/method has a test
- [ ] Watched each test fail before implementing
- [ ] Each test failed for expected reason
- [ ] Wrote minimal code to pass each test
- [ ] All tests pass
- [ ] Output has no errors or warnings这类 checklist 很适合放在 Skill 里,防止 Agent 漏掉关键步骤。
需要注意的是,每一个检查项你都得写成具体一点的动作,比如所有测试都要通过、每一个方法都要有测试。千万别写大空话,例如保证质量、遵循测试最佳实践,这样写 Agent 根本无法判定自己是否达到了对应的标准。
反馈循环
复杂任务最好不要让 Agent 一次性跑到底,而是让它在中间节点停下来验证。
更稳的写法是把循环写进 Skill:
运行 → 验证 → 修复 → 再验证比如代码审查,如果只写“请全面审查代码”,Agent 很可能一上来就开始挑命名、格式、注释,反而漏掉更重要的架构问题。
可以把审查拆成两轮:
## 代码审查流程
1. 获取变更文件列表和 diff
2. 第一轮:设计审查
- 检查整体结构是否合理
- 检查是否违反 SOLID 原则
- 如果发现明显架构问题,先报告,不急着进入细节审查
3. 第二轮:实现审查
- 检查安全风险,比如 SQL 注入、XSS、越权
- 检查性能热点,比如循环里的 DB 调用、缺失索引
- 检查异常处理和边界条件
4. 输出问题
- 标注严重等级:Critical / Warning / Suggestion
- 给出可以直接修改的建议这样写以后,Agent 的关注顺序会更稳定:先看大的设计问题,再看具体实现问题,最后再输出修改建议。
条件分支
一个 Skill 如果要处理多种情况,最好把分支写出来。别让 Agent 自己猜。
比如文档处理,创建新文档和编辑现有文档就是两条完全不同的路:
## 文档修改工作流
1. 先判断任务类型
**创建新文档?**
走创建工作流。
**编辑现有文档?**
走编辑工作流。
2. 创建工作流
- 使用模板生成文档
- 导出为目标格式
- 验证文件可以正常打开
3. 编辑工作流
- 解包现有文档
- 修改指定内容
- 每次修改后验证
- 完成后重新打包这类分支不要写得太隐晦。最好直接用“如果是 A,走 A 流程;如果是 B,走 B 流程”的形式。
如果分支越来越多,也不要全塞进 SKILL.md。主文件只保留判断逻辑,然后把具体流程拆出去:
workflows/
├── create-document.md
├── edit-document.md
└── export-document.md这样主文件不会太长,Agent 也能根据当前任务去读对应文件。
简单说,工作流解决的是“按什么顺序做”,反馈循环解决的是“做完怎么确认没跑偏”。这两块写清楚,Skill 才不容易变成一份看着很完整、执行时却经常跳步骤的说明书。
Skill 路由怎么做?
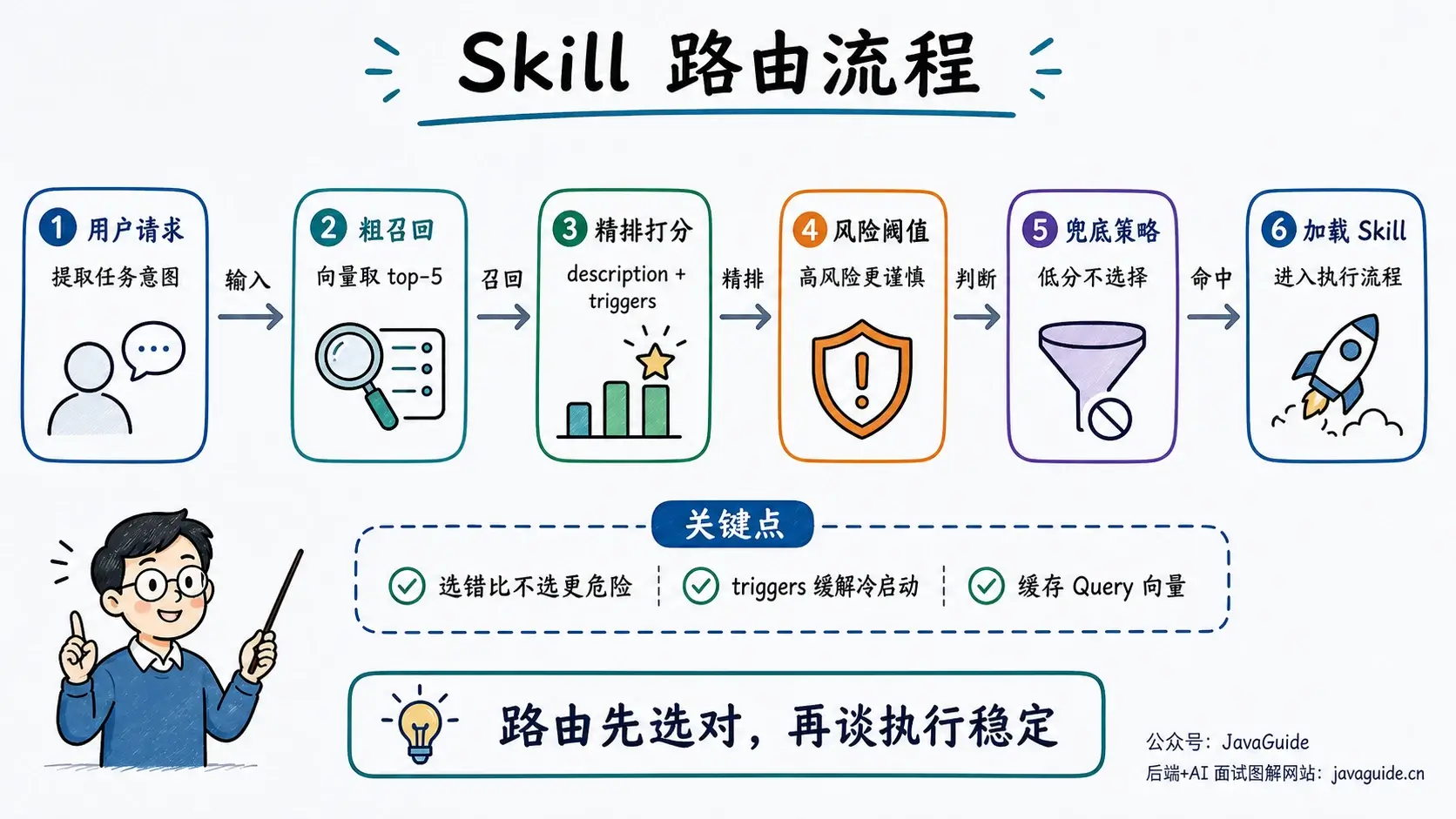
当 Skill 只有三五个时,靠模型读 description 判断就够了。数量上来以后,路由就变成一个小型检索问题。
Skill 路由和 RAG 都要“先检索,再把内容放进上下文”,但目标不一样。RAG 从大量知识里多召回几段,模型还能在生成时过滤噪声;Skill 路由面对的是数量有限、结构稳定的指令集,最怕的是选错——选错 Skill,后面的执行路径可能整条跑偏。
几十个 Skill 的规模,用轻量方案就够了:
- 粗召回: 把 Skill 的名称、description、典型 Query 样本向量化。用户请求进来后也向量化,按余弦相似度取 top-5。
- 精排: 同时命中 title、description、examples 的优先级更高;高风险 Skill(安全类、数据库类)阈值高一点。
- 兜底: 如果最高分都很低,不选任何 Skill,走默认流程。“不选”经常比“硬选一个”更安全。

冷启动问题容易被忽略:新 Skill 没有历史 Query,description 又写得太虚,向量匹配就会飘。补救方法是在元数据里加 triggers 字段:
name: jvm-runtime-diagnosis
description: Diagnose Spring Boot production runtime issues including OOM,
Full GC, high CPU, slow APIs, and thread deadlocks.
triggers:
- "接口卡死了"
- "频繁 Full GC"
- "帮我看看这段 Java 堆栈"
- "服务 OOM 了怎么排查"这些触发词会被一起向量化,相当于给冷启动的 Skill 喂了一批训练样本。
高并发场景下别过度设计,几十个 Skill 用 NumPy 在内存里算相似度就够快,真正慢的通常是外部 embedding API。先做 Query 向量缓存,收益比一上来引入 FAISS 更实在。等 Skill 数量到几百上千,再考虑 ANN 索引或专门的向量数据库。
如果要抽成一个通用调度器,建议拆成四块:注册中心维护元信息和向量,路由引擎负责召回与打分,加载器按需读取正文,上下文装配器决定最终拼到哪里。路由和加载最好解耦,这样改正文不会影响召回性能,换存储也不会动路由策略。
⭐️总结下写 Skill 时最容易踩的坑
把 Skill 当项目 README 写
README 是写给人看的,需要你写清楚项目背景、安装启动、特点等内容。Skill 不一样,它主要是写给 Agent 看的,重点在于可执行性。
一个好用的 Skill,至少要说清楚几件事:什么时候用、按什么顺序做、哪些情况别做、失败了怎么兜底。
想把一个 Skill 写得太全
很多朋友第一次写 Skill,都会想做一个“万能助手”。
代码审查也能干,数据库排查也能干,线上故障也能干,性能优化也能干,文档生成也能干。
听起来确实挺全能的。但真用起来,往往没那么好。
比如你写了一个“系统故障排查器”,里面塞了 JVM、数据库、K8s、网关、消息队列等一堆内容。用户贴一段 GC 日志,Agent 要先想:这是 JVM 问题,还是容器资源问题?用户给了一个 TraceId,它又要判断:先查链路,还是先看网关日志?用户说 Pod 一直重启,它还得从一堆数据库、MQ、网关规则里绕出来。
Skill 太大,Agent 会纠结它到底该用哪一部分,并不是直接上来就解决问题。
更好的做法是拆小一点:
jvm-metrics-analyzer:只看 JVM 指标、GC、线程栈distributed-trace-finder:只根据 TraceId 追链路耗时k8s-pod-event-viewer:只看 Pod 状态、重启原因和事件记录
这样就清楚多了。
用户贴 GC 日志,就走 JVM;给 TraceId,就走链路追踪;Pod 一直重启,就走 K8s。每个 Skill 只管一类问题,Agent 不用在一份巨大的说明书里翻来翻去。
所以,Skill 不怕小,怕的是边界不清楚。别老想着“我这个 Skill 什么都能干”,不如先把一个具体问题解决稳定。
给 Agent 太多选择
不要把一堆方案扔给 Agent,让它现场选。
人看文档时,看到 pypdf、pdfplumber、PyMuPDF、pdf2image,可能会根据经验选一个。但 Agent 不一定。你给它四个选择,它可能每次选得都不一样,甚至在一个很普通的 PDF 上也绕去用 OCR。
比如这种写法就不太好:
# ✗ 不推荐:选择太多
你可以使用 pypdf、pdfplumber、PyMuPDF 或 pdf2image 处理 PDF。更好的写法是:先给默认方案,再给例外情况。
# ✓ 推荐:默认方案 + 兜底方案
默认使用 pdfplumber 提取文本。
如果是扫描版 PDF,需要 OCR,再改用 pdf2image + pytesseract。Skill 里不要每一步都让 Agent 做技术选型。大部分时候,你直接告诉它“正常情况走哪条路,什么情况再换方案”就够了。
术语别来回换
同一个概念,在一个 Skill 里尽量只用一个名字,例如你前面用到了 API 端点,后面就不要再写成 URL、API 路由或路径了。
这个问题看起来很小,但真会影响 Agent 执行。
人能看出来“URL”“路径”“API 路由”大概是在说同一类东西,Agent 有时候也能看出来,但不一定每次都稳定。尤其是 Skill 里还有判断条件时,术语一混,规则就容易飘。
所以别追求文采,也别怕重复。Skill 不是作文,同一个概念反复用同一个词,反而是好事。
让 LLM 做确定性工作
格式转换、精确计算、批量文件处理、会改数据的操作,能交给脚本就交给脚本。
- LLM 更适合做判断:读懂任务、提取参数、决定下一步、解释结果。
- 脚本更适合做执行:解析文件、转换格式、批量处理、校验输出。
比如文件处理,就不要让 Agent 自己猜异常原因。能在脚本里处理的,就在脚本里写清楚:
# ✓ 推荐:错误条件写清楚
def process_file(path):
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
print(f"未找到文件 {path},正在创建默认文件")
with open(path, "w") as f:
f.write("")
return ""下面这种就不太行:
# ✗ 不推荐:直接崩,Agent 只能猜原因
def process_file(path):
return open(path).read()配置参数也尽量自解释,不要留一堆魔法数字:
# ✓ 推荐:能看出为什么这样配
REQUEST_TIMEOUT = 30 # HTTP 请求通常应在 30 秒内完成
MAX_RETRIES = 3 # 三次重试在可靠性和耗时之间比较均衡总结
别把 Prompt、Function Calling、MCP、Skills 混成一回事。
简单说,Prompt 是用户这次要做什么;Function Calling 是模型怎么发起工具调用;MCP 是把文件、数据库、GitHub 这类外部能力接进来;Skills 则是把一类任务的流程、规则和经验沉淀下来,让 Agent 需要时再读。
写 Skill 时重点记住几点:
第一,description 要写准。它决定 Agent 什么时候会想到这个 Skill。别写“帮助处理文档”这种空话,要写清楚“做什么 + 什么时候用”。
第二,正文别写成 README。Agent 不需要科普,真正值钱的是项目里的特殊约定、执行步骤、失败处理和踩坑提醒。
第三,主文件别太长。SKILL.md 放主流程,细节拆到 references/、scripts/ 里按需读取。
第四,不同任务给不同自由度。迁移、部署、删文件这类高风险操作要写死步骤;代码审查、方案评估这类任务可以给方向,让 Agent 自己判断。
第五,复杂任务要有验证点。别让 Agent 一路跑到底就说完成了,该跑测试、该检查输出、该失败重试,都要写进流程里。
第六,写第一个 Skill 时,先看官方 skill-creator。它比普通模板更有价值,因为它会逼你先想清楚触发条件、任务边界和文件拆分。
最后,第三方 Skill 不要直接拿来就用。SKILL.md 也是指令,里面可能夹带不安全操作。企业里至少要审一遍正文、脚本和参考文件。
一个好 Skill,是一份能让 Agent 稳定干活的工作手册。
参考
- Anthropic 官方 Skills 仓库:https://github.com/anthropics/skills
- Anthropic 官方 skill-creator:https://github.com/anthropics/skills/blob/main/skills/skill-creator/SKILL.md
- Superpowers:https://github.com/obra/superpowers
- sanyuan-skills:https://github.com/sanyuan0704/sanyuan-skills
- Everything Claude Code:https://github.com/nicekid1/everything-claude-code
- skills.sh(查找现成 Skills 的平台):https://skills.sh/
写在最后
如果内容对你有帮助的话,欢迎顺手给 JavaGuide 点一个免费的 Star 支持一下:GitHub | Gitee。
JavaGuide 已持续维护近七年,累计 6100+ 次提交,来自 620+ 位贡献者共同完善。你的 Star、反馈和 PR,都是这个项目继续更新的动力。
如果你正在准备后端/AI 应用开发面试,也可以了解一下我的知识星球,里面包括后端和 AI 实战项目、简历优化、一对一提问和高频考点资料,已经持续维护六年。