ZAB 协议详解:ZooKeeper 原子广播、消息广播、崩溃恢复与 Leader 选举
作为一款极其优秀的分布式协调框架,ZooKeeper 的高可用和数据一致性备受业界推崇。很多人误以为 ZooKeeper 使用的是大名鼎鼎的 Paxos 算法,但实际上,它的“灵魂”是一个专门为其定制的共识协议——ZAB(ZooKeeper Atomic Broadcast,原子广播协议)。
ZAB 并非像 Paxos 那样是通用的分布式一致性算法,它是一种特别为 ZooKeeper 设计的、支持崩溃可恢复的原子消息广播算法。基于 ZAB 协议,ZooKeeper 实现了一种主备模式的架构,来保持集群中各个副本之间的数据一致性。
这篇文章只讲 ZAB 的协议过程。如果你还不熟悉 ZooKeeper 的 ZNode、Watcher、Session 和应用场景,建议先读 ZooKeeper 入门指南。如果你想先理解 Leader、Quorum 和脑裂这些通用问题,可以先读 分布式协调详解。
ZAB 集群的核心角色与状态
在深入协议运作之前,我们需要先了解 ZooKeeper 集群中的三个主要角色:
- Leader(领导者): 集群中唯一的写请求处理者。它负责发起投票和协调事务,所有的写操作都必须经过 Leader。
- Follower(跟随者): 可以直接处理客户端的读请求。收到写请求时,会将其转发给 Leader。在 Leader 选举过程中,Follower 拥有选举权和被选举权。
- Observer(观察者): 功能与 Follower 类似,但没有选举权和被选举权。它的存在是为了在不影响集群共识性能(即不增加需要等待的投票数)的前提下,横向扩展集群的读性能。
对应的,集群中的节点通常处于以下四种状态之一:
LOOKING:寻找 Leader 状态(正在进行选举)。LEADING:当前节点是 Leader,正在领导集群。FOLLOWING:当前节点是 Follower,服从 Leader 领导。OBSERVING:当前节点是 Observer。
核心标识:ZXID 与 Epoch
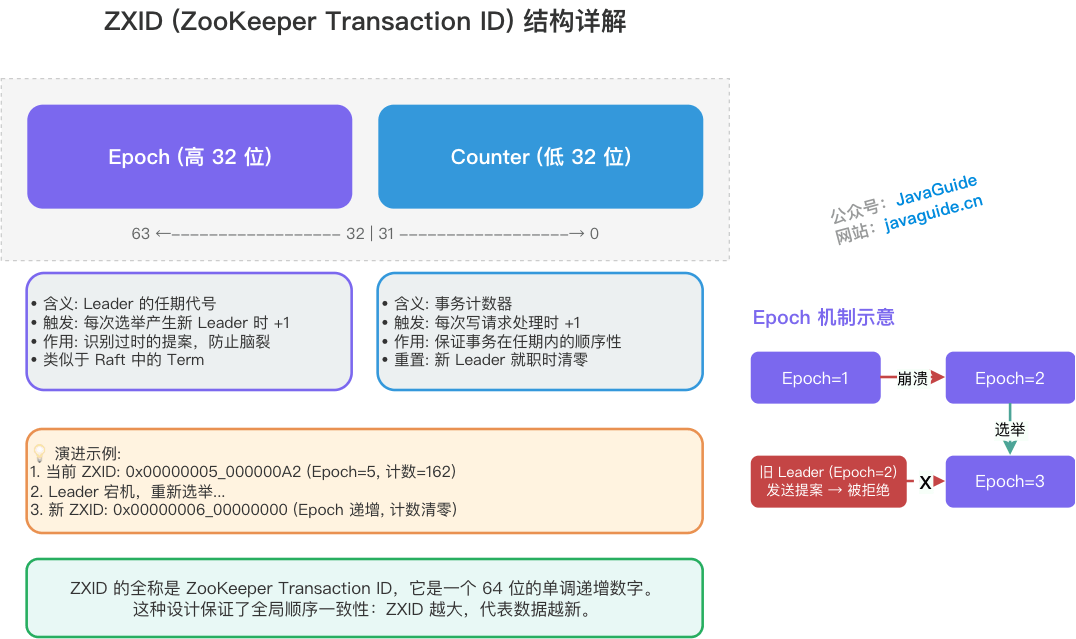
为了保证分布式环境下消息的绝对顺序性,ZAB 协议引入了一个全局单调递增的事务 ID——ZXID。
ZXID 是一个 64 位的长整型(long):
- 高 32 位(Epoch 纪元): 代表当前 Leader 的任期年代。当选出一个新的 Leader 时,Epoch 就会在前一个的基础上加 1。这相当于朝代更替。
- 低 32 位(事务 ID): 一个简单的递增计数器。针对客户端的每一个写请求,计数器都会加 1。新 Leader 上位时,这个低 32 位会被清零重置。
ZAB 的两种基本模式
ZAB 协议的运作可以精简为两种基本模式的交替:消息广播(正常工作状态)和崩溃恢复(异常或启动状态)。
1. 消息广播模式(正常处理写请求)
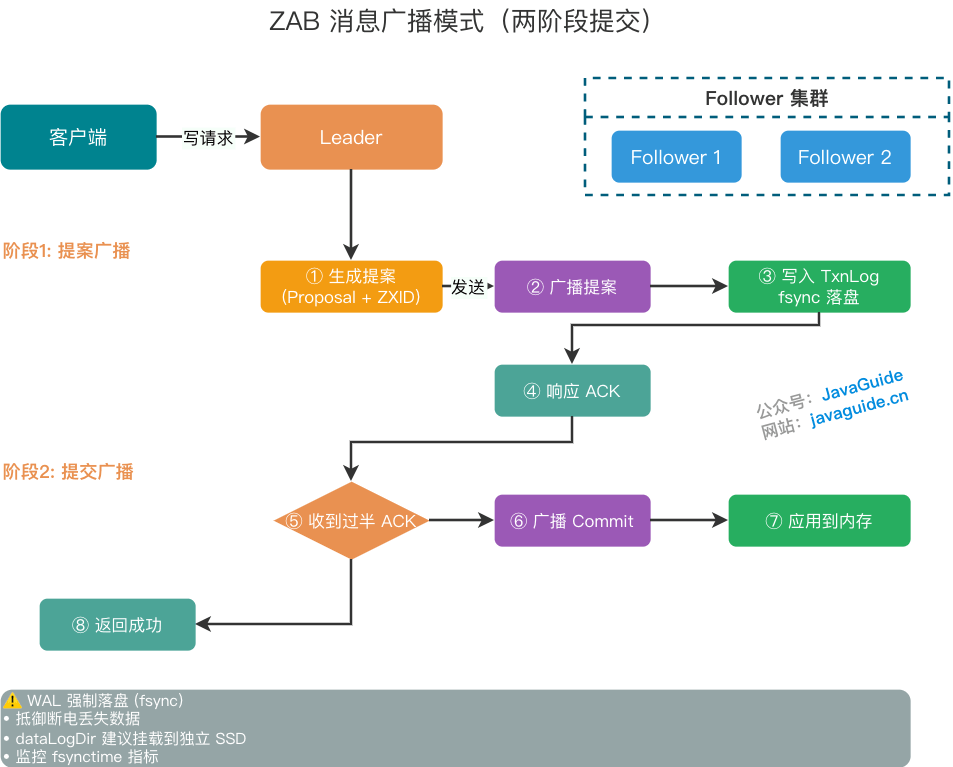
当集群拥有健康的 Leader,且过半的节点完成了状态同步后,就会进入消息广播模式。这个过程类似于一个简化的“两阶段提交(2PC)”:
- 生成提案: Leader 接收到写请求后,将其转化为一个带有 ZXID 的提案(Proposal)。
- 顺序发送: Leader 为每个 Follower 维护了一个先进先出(FIFO)的网络队列(基于 TCP 协议),确保提案按生成顺序发送给 Follower。
- 写入与反馈(WAL 强制落盘): Follower 收到提案后,必须将其追加到本地的事务日志(TxnLog)中,并强制执行系统调用
fsync将内核缓冲区的数据物理刷入磁盘。只有确认数据切实落盘,才会向 Leader 响应ACK。这一过程是 ZAB 抵御断电丢失数据的核心防线。因此,在物理部署上,强烈建议将 ZooKeeper 的事务日志目录(dataLogDir)挂载到独立且无锁的 SSD 上,避免与其他高 I/O 进程争用磁盘,从而规避因fsync阻塞导致的 P99 响应时间恶化。生产环境中必须重点监控节点的fsynctime指标,若平均刷盘耗时经常超过 100ms,集群随时可能崩溃。 - 广播提交: 当 Leader 收到过半数 节点的
ACK响应后,就会认为该写操作成功。Leader 在本地写日志时会更新内部的 quorum 计数器(而非显式向自己发送 ACK),确认过半后向客户端返回成功响应,并向所有节点广播Commit消息。Follower 收到Commit后,正式将数据应用到内存中。
2. 崩溃恢复模式(Leader 宕机或网络异常)
当系统刚启动,或者 Leader 服务器崩溃、与过半 Follower 失去联系时,整个集群就会暂停对外服务,进入 LOOKING 状态,触发崩溃恢复模式。崩溃恢复主要包含两个阶段:Leader 选举和数据恢复。
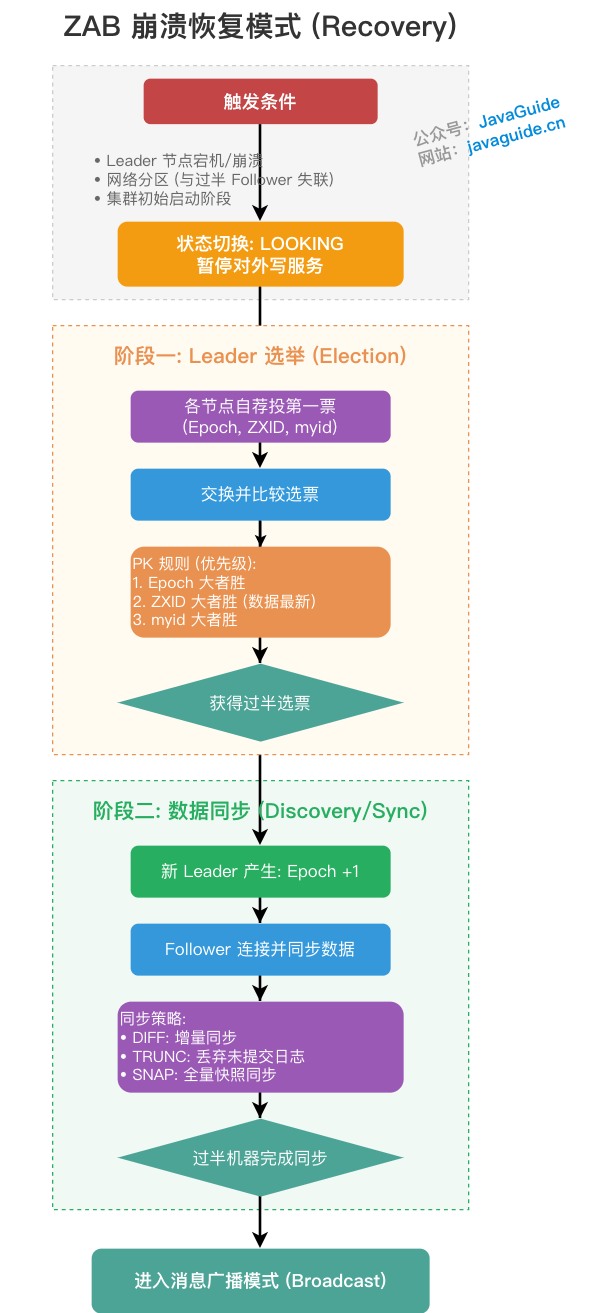
阶段一:Leader 选举
选举的核心原则是:拥有最新数据的节点优先当选。 每个节点都会先投自己一票,投票信息包含 (Epoch, ZXID, myid)。随后节点会交换选票,并按照以下顺序进行 PK:
- 比较 Epoch: 纪元大的优先。
- 比较 ZXID: 如果 Epoch 相同,ZXID 大的优先(代表数据越新)。
- 比较 myid: 如果前两者都相同,服务器唯一标识
myid大的优先。
一旦某个节点获得了过半数的选票,它就会成为新的 Leader。(这也是为什么 ZooKeeper 推荐部署奇数台服务器的原因,能以最低的成本实现半数以上的容错。)
阶段二:数据恢复
选出新 Leader 只是第一步,为了保证数据一致性,ZAB 必须在数据同步阶段实现两个极其重要的保证:
- 确保已经在旧 Leader 上提交的事务,最终被所有节点提交。 (防止数据丢失)
- 丢弃那些只在旧 Leader 上提出,但还没来得及提交的事务。 (防止脏数据干扰)
新 Leader 会找到当前最大的 Epoch 并加 1 作为新纪元,随后与所有 Follower 进行比对。Follower 会发送自己事务日志中最新记录的 lastZxid(包含已提议但尚未提交的提案),Leader 根据这个值采取多态同步策略:差异化增量同步(DIFF)、强制丢弃未提交日志(TRUNC) 或 全量快照传输(SNAP)。
这一设计至关重要:Leader 需要准确识别 Follower 日志中是否残留着旧 Leader 未完成提交的“幽灵提案”,才能正确下发 TRUNC 指令让其截断回滚。如果只上报已提交的 ZXID,这些未提交的脏数据将无法被感知,TRUNC 分支就永远不会被触发。
更关键的是,此时新的 Epoch 已经生效。若原 Leader 因 JVM 触发长达数十秒的 Full GC 而发生“假死”,当其苏醒并试图向集群下发旧 Epoch 的提案时,由于过半节点已记录了更高的新 Epoch 且已向新 Leader 提交 quorum,这些幽灵提案将被节点无情拒绝并抛弃。ZAB 正是通过 Epoch 机制 + 多数派 quorum 的组合,从根本上免疫了网络环境下的脑裂现象——单靠 Epoch 拒绝还不够,必须有过半节点已经连上新 Leader,旧 Leader 才真正失去写入能力。
当过半的机器与新 Leader 完成了状态和数据同步,ZAB 协议就会平滑退出崩溃恢复模式,重新进入消息广播模式。
与 Raft 对比
ZAB 与 Raft 的高度相似性: 如果你了解过 Raft 算法,会发现它们非常相似。它们都有唯一的主节点,都使用 Epoch/Term 来标识任期,并且都采用了只要半数以上节点确认即可提交的策略。这说明在现代分布式共识领域,这种基于主备和多数派选举的架构已经成为了事实上的标准。
在当前的分布式系统实践中,Raft 算法通常被视为比 ZAB 更实用和受欢迎的选择。 这是因为 Raft 从设计之初就强调易懂性和可实现性,它将领导者选举、日志复制和安全性明确分离,这使得开发者更容易正确实施和调试,而 ZAB 作为 ZooKeeper 的专有协议,更侧重于原子广播的特定需求,导致其通用性较差。
Raft 已广泛应用于现代系统,如 Kubernetes 的 etcd、Hashicorp Consul、Apache Kafka(在其 KIP-500 版本中去除 ZooKeeper 依赖,转向 Raft-based KRaft)、TiKV 等,这极大“民主化”了分布式共识的开发。
相比之下,ZAB 主要绑定在 ZooKeeper 上,虽然 ZooKeeper 仍是经典的协调服务,但许多新项目倾向于选择 Raft 以避免 ZooKeeper 的额外复杂性和潜在瓶颈(如在大规模下共识开销)。
此外,Raft 的社区支持更活跃,衍生出多种优化变体(如用于区块链的改进版本),使其在效率和适用场景上更具优势。 然而,如果你的系统已深度集成 ZooKeeper,ZAB 仍是最优化的选择;否则,对于新设计或通用共识需求,Raft 是当前更实用的标准。
总结
ZAB 协议通过精心设计的 Leader 选举和多数派确认机制,在分布式系统的分区容错性(P)和一致性(C)之间做出了选择(满足 CP 属性)。当出现网络分区时,ZAB 宁愿牺牲短暂的可用性(A)进行选举,也要保证数据的一致性。
需要特别强调的是,ZAB 协议默认不保证严格的强一致性(线性一致性),而是提供顺序一致性(Sequential Consistency)。
由于 Follower 可以直接处理客户端的读请求且不强求数据绝对同步,客户端完全可能读取到落后于 Leader 的陈旧数据(Stale Read)。在生产环境中,若业务涉及如分布式锁等对数据新鲜度要求极高的场景,必须在执行 read() 操作前显式调用 sync() 原语,强制要求连接的 Follower 追平 Leader 的事务状态机。
当发生网络分区时,客户端若连接至被隔离的少数派 Follower,虽然写操作会失败,但仍可读出过期数据,这是使用 ZAB 协议时必须考虑的边界场景。